

Vector Search and Embeddings in Fuego
Overview
Fuego provides powerful built-in tools for working with vector embeddings and performing semantic search in Firestore. Vector search enables you to find documents based on similarity rather than exact matches, making it ideal for AI-powered applications like recommendation systems, semantic search, and content discovery.
With Fuego’s vector search capabilities, you can generate embeddings using multiple AI providers, store them in Firestore vector fields, and query them using nearest-neighbor search—all through an intuitive visual interface.
Use cases:
- Semantic search across documents, products, or articles
- Content recommendation based on similarity
- Duplicate detection and clustering
- Text similarity matching
- Building RAG (Retrieval Augmented Generation) systems
Prerequisites
Before using vector search in Fuego:
- Firestore database
- Fuego installed and connected to your Firebase project
- API keys for your chosen AI provider (OpenAI or compatible provider, Gemini, Ollama, or Vertex AI)
- Collections with documents containing text fields to convert into embeddings
- Basic understanding of vector embeddings and semantic search concepts
Core concepts
What are vector embeddings?
Vector embeddings are numerical representations of text, images, or other data types in a high-dimensional space. Items with similar meanings are located close to each other in this space, enabling similarity-based search.
For example, the texts “dog” and “puppy” would have embeddings closer together than “dog” and “car.”
AI providers in Fuego
Fuego supports multiple AI providers for generating embeddings:
- OpenAI: Industry-leading models like
text-embedding-3-smallandtext-embedding-3-large - Gemini: Google’s embedding models including
gemini-embedding-001 - Ollama: Self-hosted, local models for privacy-focused implementations
- Vertex AI: Google Cloud’s managed AI platform with enterprise features
- OpenAI-compatible providers: Any service implementing OpenAI’s embedding API
Each provider offers different embedding models with varying dimensions, performance characteristics, and costs.
Vector fields in Firestore
Firestore supports native vector fields that can store embeddings and be queried using the findNearest operation. Vector fields have the following properties:
- Dimension: The number of values in the vector (e.g., 1024, 768, 2048)
- Distance metric: How similarity is calculated (cosine, euclidean, dot product)
- Indexing: Automatic indexing for efficient nearest-neighbor queries
Setting up AI providers
Configuring a new provider
To start using vector search in Fuego, first configure an AI provider:
- Navigate to AI settings: Click on the AI tab in the top navigation bar in settings sidebar
- Add a provider: Click the + Add provider button
- Select your provider: Choose from OpenAI, Gemini, Ollama, or Vertex AI
- Enter credentials:
- Display name: A friendly name for this configuration (e.g., “My personal project”)
- API key: Your provider’s API key (Vertex AI requires additional fields like Project ID and Location)
- Encrypt API key: Toggle to encrypt the key (recommended for security)
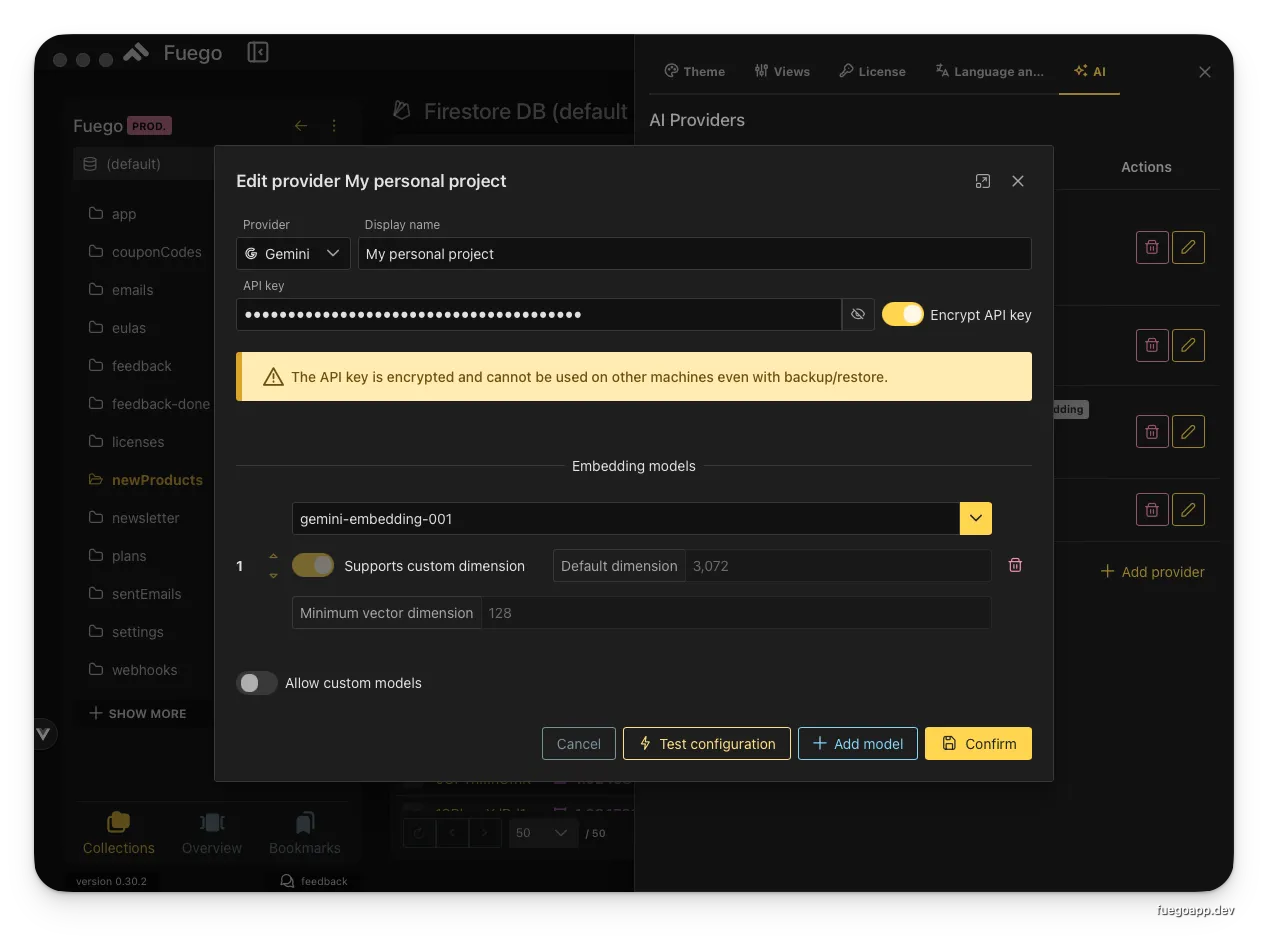 Configuring a Gemini provider with encrypted API key
Configuring a Gemini provider with encrypted API key
⚠️ Important: When encryption is enabled, the API key is encrypted and bound to your machine. You cannot use the same configuration on different machines, even with backup/restore operations. Keep unencrypted backups of your keys in a secure password manager.
Configuring embedding models
After adding a provider, configure which embedding models to use:
- Select embedding model: Choose from available models (e.g.,
gemini-embedding-001,text-embedding-3-small) - Custom dimensions (if supported):
- Toggle Supports custom dimension for models that allow dimension specification
- Set Default dimension (e.g., 2048, 1024, 768)
- Set Minimum vector dimension to enforce constraints (e.g., 128)
- Test configuration: Click Test configuration to verify the setup
- Save: Click Confirm to save your provider settings
Example providers configuration:
| Provider | Model | Dimensions | Use Case |
|---|---|---|---|
| OpenAI | text-embedding-3-small | 1024 | Fast, cost-effective search |
| OpenAI | text-embedding-3-large | 3072 | High-accuracy semantic search. Firestore supports max 2048 |
| Gemini | gemini-embedding-001 | 768 | Balanced performance |
| Ollama | embeddinggemma | Custom | Privacy-focused, local deployment |
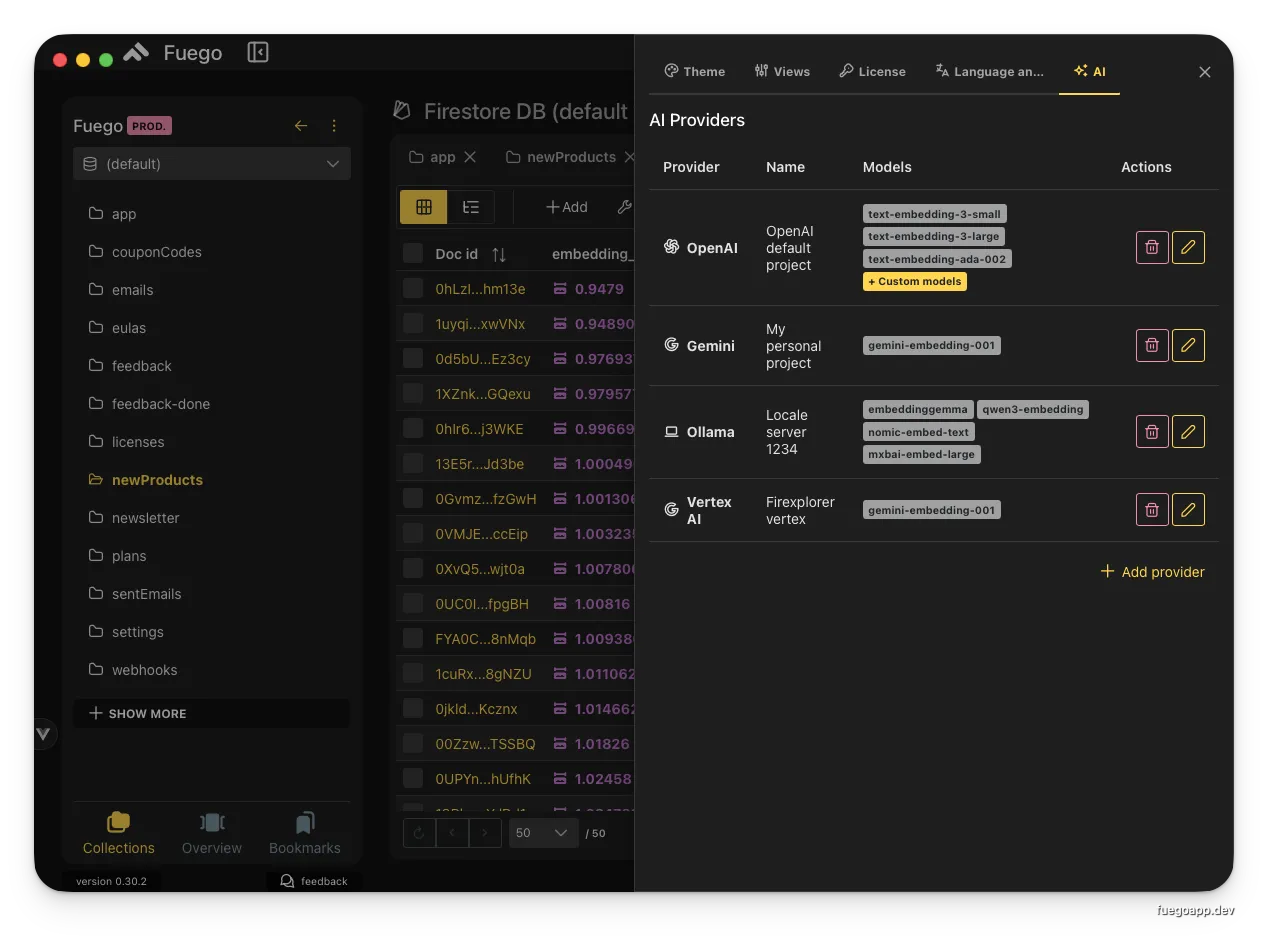 Multiple configured AI providers with different embedding models
Multiple configured AI providers with different embedding models
Creating embeddings
Manual embedding creation
Create embeddings for testing or one-off operations:
- Open the create dialog: In any collection view, click the Actions menu and select Create embedding
- Select provider and model: Choose your AI provider and embedding model
- Enter text: Type or paste the text to convert into an embedding
- Select distance metric: Choose the similarity calculation method (Cosine, Euclidean, Dot Product)
- Generate: Click Confirm to create the embedding
The generated embedding vector will be displayed and can be used immediately for search queries.
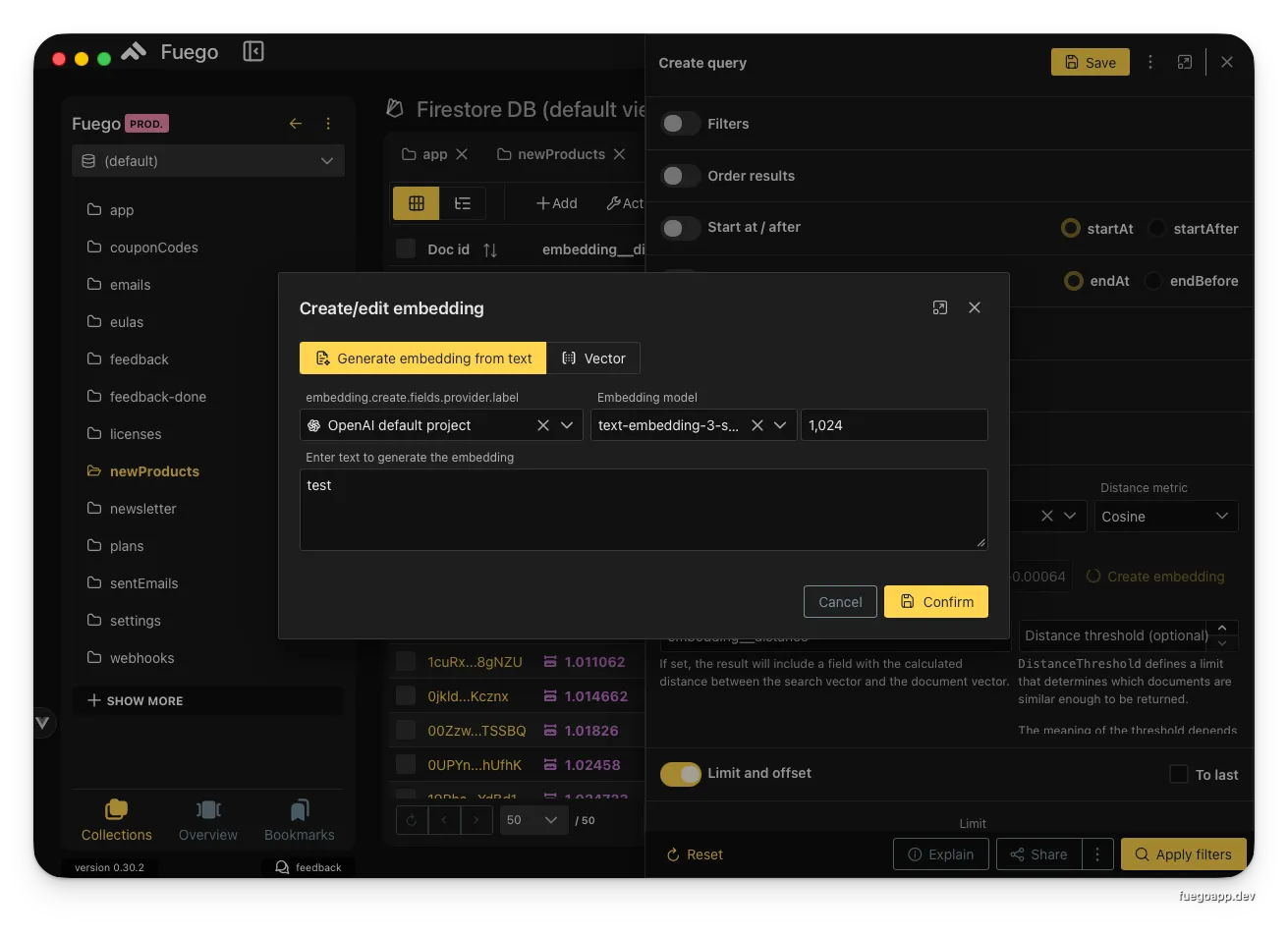 Creating an embedding from text using OpenAI’s text-embedding-3-small model
Creating an embedding from text using OpenAI’s text-embedding-3-small model
Distance metrics explained:
- Cosine similarity: Measures the angle between vectors (best for text similarity)
- Euclidean distance: Measures straight-line distance (good for spatial data)
- Dot product: Measures vector alignment (useful for normalized vectors)
Batch embedding creation
Convert existing document fields into embeddings at scale:
- Select documents: Filter or select the documents you want to process
- Open batch actions: Click the Actions menu
- Choose “Create embeddings”: Select the batch embedding operation
- Configure the update:
- Update attribute: Choose or create the field to store embeddings (e.g.,
embedding) - Create if not exists: Toggle to add the field to documents that don’t have it
- Update method: Select Embedding
- Source field: Choose the text field to convert (e.g.,
description,name,content) - Provider and model: Select your AI provider and embedding model
- Dimensions: Specify the vector dimensions (e.g., 1024)
- Update attribute: Choose or create the field to store embeddings (e.g.,
- Confirm: Click Confirm to start the batch operation
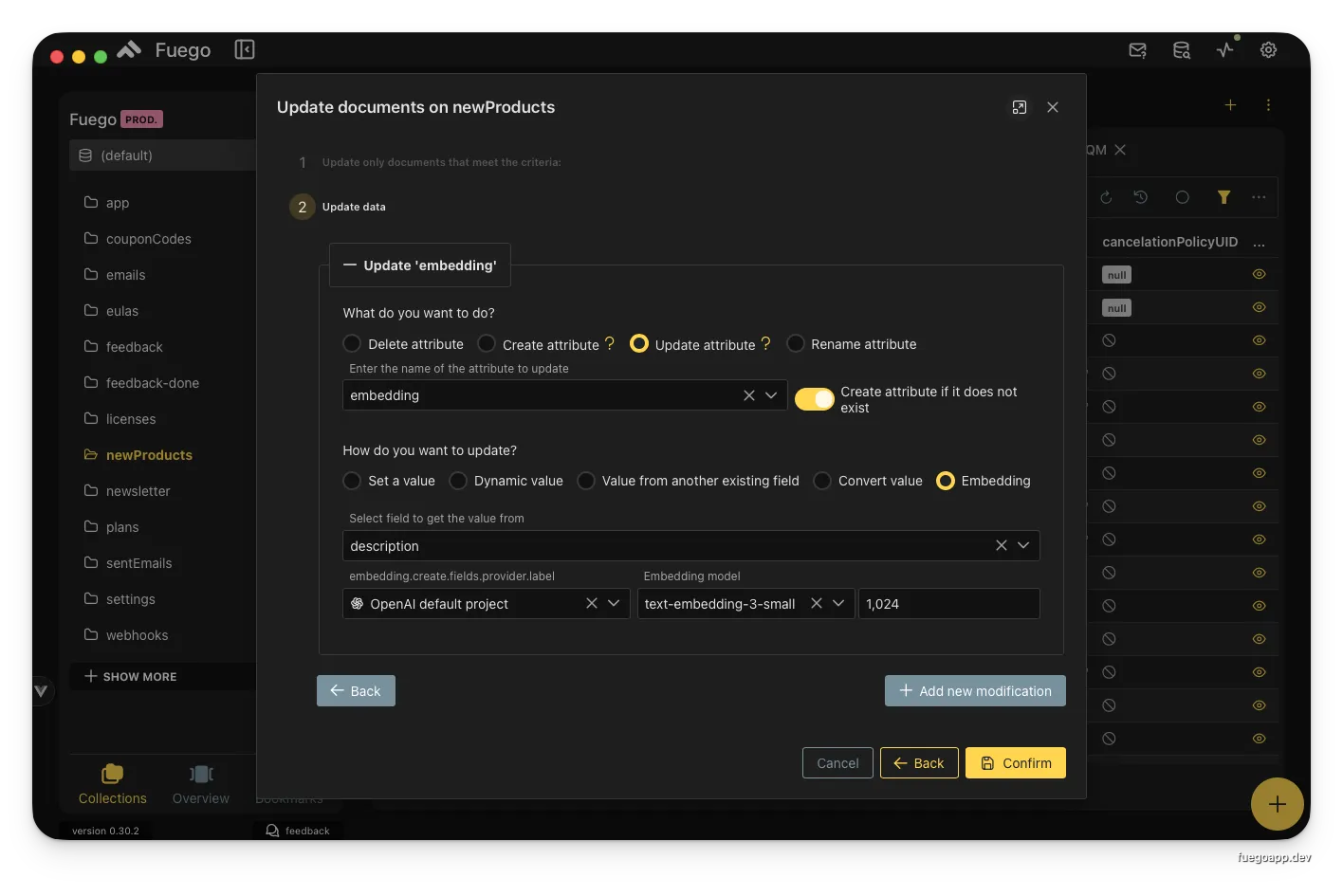 Batch updating documents to create embeddings from the description field
Batch updating documents to create embeddings from the description field
✅ Best Practice: Process embeddings in batches of 50-100 documents to avoid rate limiting and monitor costs. Use the Limit setting in the batch action dialog to control batch size.
Example workflow:
// This is what Fuego does behind the scenes
import { collection, query, getDocs, updateDoc } from "firebase/firestore";
const createEmbeddingsForCollection = async (
collectionRef: CollectionReference,
sourceField: string,
targetField: string,
provider: EmbeddingProvider,
) => {
const snapshot = await getDocs(collectionRef);
for (const doc of snapshot.docs) {
const text = doc.data()[sourceField];
if (text && typeof text === "string") {
// Generate embedding using AI provider
const embedding = await provider.generateEmbedding(text);
// Update document with vector field
await updateDoc(doc.ref, {
[targetField]: embedding,
});
}
}
};
Performing vector search
Creating a vector search query
Use the findNearest operation to perform semantic similarity search:
- Create a new query: Click the query builder icon
- Enable vector search: Toggle Vector search (find nearest)
- Configure the query:
- Attribute: Select the vector field containing embeddings (e.g.,
embedding) - Search vector: Click Create embedding to generate a query vector from text
- Distance metric: Choose your similarity metric (Cosine, Euclidean, Dot Product)
- Result distance field name: Name for the calculated distance field (e.g.,
embedding_distance) - Distance threshold (optional): Limit results to those within a certain similarity threshold
- Attribute: Select the vector field containing embeddings (e.g.,
- Set limits: Define the maximum number of results to return
- Execute: Click Apply filters to run the search
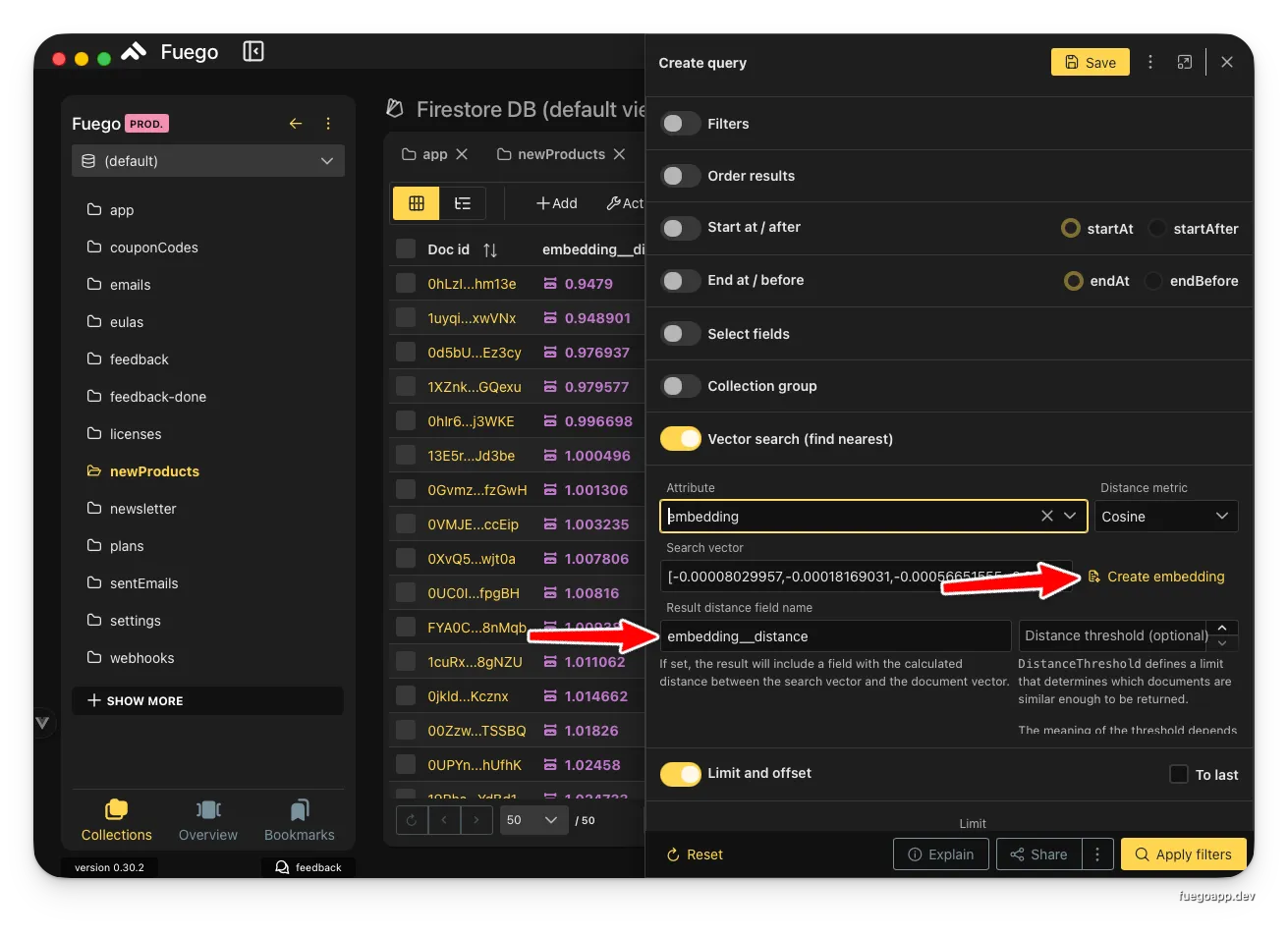 Configuring a findNearest query with cosine similarity and distance threshold
Configuring a findNearest query with cosine similarity and distance threshold
Understanding search results
Query results include your original document fields plus the calculated distance:
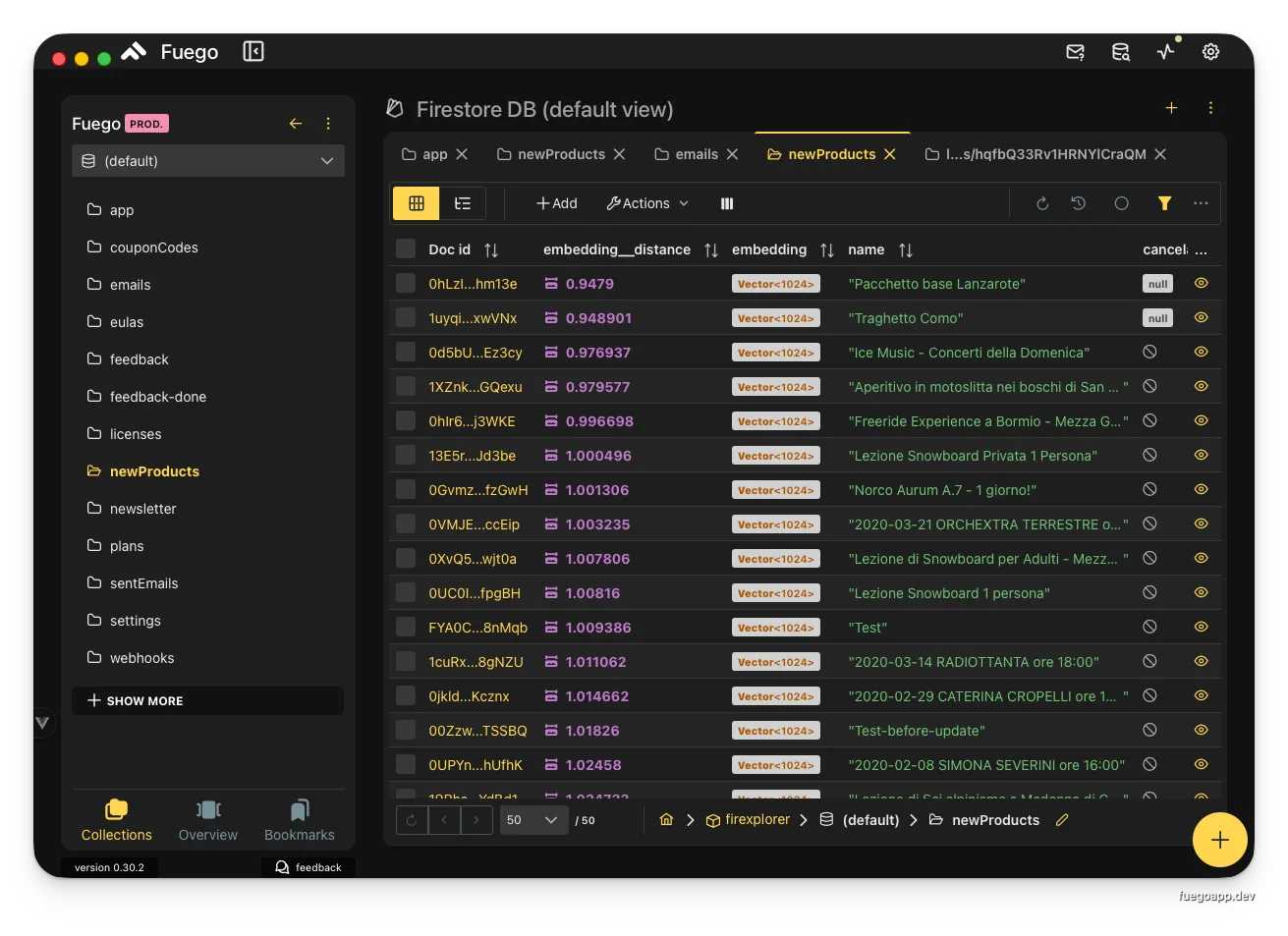 Search results showing embedding vectors and calculated distances
Search results showing embedding vectors and calculated distances
The results are automatically sorted by similarity (closest first). Each document includes:
- Original fields: All document data (name, description, etc.)
- Embedding vector: The stored vector field (displayed with orange badge)
- Distance field: Calculated similarity score (lower = more similar for Euclidean and Cosine)
Interpreting distance values:
- Cosine similarity: 0 = identical, 2 = opposite, typically 0-1 for similar items
- Euclidean distance: Lower values = more similar, no fixed upper bound
- Dot product: Higher values = more similar (for normalized vectors)
Advanced usage
Hybrid search (combining filters with vector search)
Combine traditional Firestore queries with vector search for powerful hybrid queries:
- Set up filters: Add
whereclauses for exact matching - Add vector search: Enable
findNearestfor semantic matching - Order and limit: Control result ordering and pagination
This approach lets you filter by category, date, or status, then find semantically similar items within those results.
Example use case: “Find the 10 most similar products to this description, but only from the ‘electronics’ category and in stock.”
Custom vector dimensions
When your AI provider supports custom dimensions, you can optimize for your specific use case:
Higher dimensions (…2048):
- More accurate similarity matching
- Better captures nuanced differences
- Higher storage and computation costs
- Slower query performance
Lower dimensions (512, 768):
- Faster queries and updates
- Lower storage costs
- Good for large-scale deployments
- May miss subtle semantic differences
Balanced approach (1024):
- Good trade-off between accuracy and performance
- Recommended starting point for most applications
Distance thresholds
Use distance thresholds to filter out low-quality matches:
// Conceptual example of what Fuego implements
const searchWithThreshold = async (
queryVector: number[],
threshold: number,
) => {
// In Fuego, you set this in the UI
// Results automatically filtered to distance < threshold
const results = await findNearest(
collection(db, "products"),
"embedding",
queryVector,
{
distanceThreshold: threshold,
limit: 20,
},
);
return results;
};
Recommended thresholds:
- Cosine: 0.2-0.4 for strict similarity, 0.6-0.8 for broader matches
- Euclidean: Varies by dimension; start with 1.0 and adjust based on results
- Dot product: Depends on vector normalization
Complete example
Here’s a complete workflow for implementing semantic search in a product catalog:
Step 1: Configure AI provider
1. Navigate to AI → Add provider
2. Select "OpenAI"
3. Display name: "Production OpenAI"
4. API key:
5. Enable encryption
6. Add model: text-embedding-3-small (1024 dimensions)
7. Test and confirm
Step 2: Generate embeddings for existing products
1. Open the 'products' collection
2. Verify all products have 'description' field
3. Actions → Batch update
4. Update field: embedding
5. Source: description
6. Provider: Production OpenAI
7. Model: text-embedding-3-small
8. Dimensions: 1024
9. Process in batches of 50
Step 3: Implement search in your application
import { collection, query, limit, vectorQuery } from "firebase/firestore";
interface SearchOptions {
queryText: string;
maxResults: number;
category?: string;
threshold?: number;
}
const searchProducts = async (options: SearchOptions) => {
const { queryText, maxResults, category, threshold } = options;
// Generate embedding for search query
const queryEmbedding = await generateEmbedding(queryText);
// Build the query
let productsQuery = collection(db, "products");
// Optional: Add category filter
if (category) {
productsQuery = query(productsQuery, where("category", "==", category));
}
// Perform vector search
const vectorSearchQuery = query(
productsQuery,
findNearest("embedding", queryEmbedding, {
limit: maxResults,
distanceField: "similarity",
distanceThreshold: threshold || 0.5,
}),
);
const snapshot = await getDocs(vectorSearchQuery);
return snapshot.docs.map((doc) => ({
id: doc.id,
...doc.data(),
// similarity field automatically added by findNearest
}));
};
// Helper function to generate embeddings
const generateEmbedding = async (text: string): Promise => {
const response = await fetch("https://api.openai.com/v1/embeddings", {
method: "POST",
headers: {
"Content-Type": "application/json",
Authorization: `Bearer ${process.env.OPENAI_API_KEY}`,
},
body: JSON.stringify({
model: "text-embedding-3-small",
input: text,
dimensions: 1024,
}),
});
const data = await response.json();
return data.data[0].embedding;
};
// Usage example
const results = await searchProducts({
queryText: "wireless headphones with noise cancellation",
maxResults: 10,
category: "electronics",
threshold: 0.3,
});
console.log("Found products:", results);
Step 4: Display results in your UI
// React component example
import { useState } from 'react';
const ProductSearch = () => {
const [query, setQuery] = useState('');
const [results, setResults] = useState([]);
const [loading, setLoading] = useState(false);
const handleSearch = async () => {
setLoading(true);
try {
const products = await searchProducts({
queryText: query,
maxResults: 20,
threshold: 0.4
});
setResults(products);
} catch (error) {
console.error('Search failed:', error);
} finally {
setLoading(false);
}
};
return (
<input
type="text"
value={query}
onChange={(e) => setQuery(e.target.value)}
placeholder="Describe what you're looking for..."
/>
{loading ? 'Searching...' : 'Search'}
{results.map(product => (
{product.name}
{product.description}
Similarity: {(1 - product.similarity).toFixed(2)}
))}
);
};
Troubleshooting
Embeddings not generating
Symptoms: Batch operation completes but no embeddings are created
Solution:
- Verify the source field exists and contains text
- Check that documents aren’t empty or null
- Review the AI provider’s API status
- Check Fuego’s console for error messages
- Test with a small batch (1-2 documents) first
Poor search results
Symptoms: Search returns irrelevant or unexpected results
Solution:
- Verify you’re using the same embedding model for both storage and search
- Check that dimension counts match
- Try different distance metrics (cosine usually works best for text)
- Adjust your distance threshold
- Review the quality of your source text data
- Consider using a higher-dimensional model for better accuracy
High costs
Symptoms: Unexpectedly high bills from AI provider
Solution:
- Audit your embedding generation frequency
- Implement caching for common queries
- Only regenerate embeddings when content changes
- Use smaller embedding models for less critical features
- Consider local models (Ollama) for development
- Set up billing alerts in your provider dashboard
Slow queries
Symptoms: Vector search queries take several seconds to complete
Solution:
- Reduce the number of documents being searched
- Use collection partitioning for large datasets
- Implement pagination with reasonable limits
- Consider using lower-dimensional embeddings
- Verify Firestore indexes are properly created
- Use composite queries to filter before vector search
Limitations
- Maximum vector dimensions: Firestore supports up to 2048 dimensions (as of 2025)
- Query limits: Vector search queries are subject to standard Firestore query limits
- No vector field updates in batched writes: Vector fields cannot be updated using batched writes
- Cost considerations: AI provider API calls and Firestore operations incur costs
- Index limitations: Each collection can have a limited number of indexed vector fields
- Rate limits: AI providers impose rate limits on embedding generation

